Embark on a journey of brand empowerment as https://urlDNA.io introduces its latest feature that places the reins firmly in the hands of users – brand monitoring! This function is crafted to endow esteemed users with the ability to effortlessly keep a watchful eye on their brand. And the cherry on top? It’s completely free for all registered members.
Ready to take charge? Dive into the world of brand monitoring at https://urldna.io
Here’s a quick rundown of how this game-changer operates:
How It Works:
Monitoring a brand has never been smoother. Just a handful of easy steps stand between users and brand vigilance:
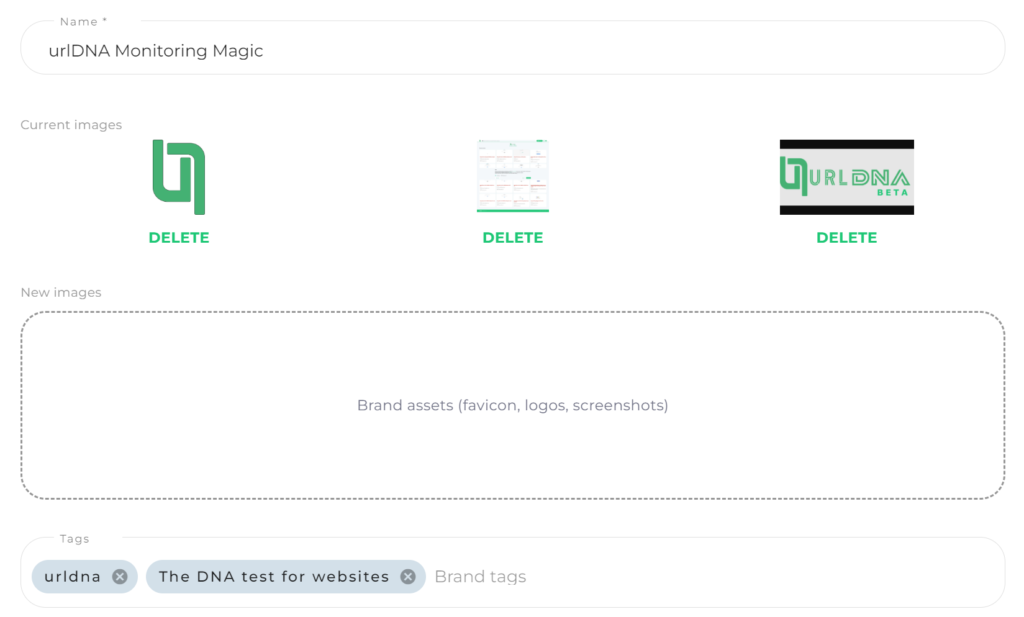
Rule Name:
Craft a snappy and unforgettable name for the monitoring rule. Let’s concoct a rule for the urlDNA brand – “urlDNA Monitoring Magic.”
Brand Assets:
Share the visual essence of the brand. Upload screenshots, logos, favicons – every element that defines the uniqueness of urlDNA. Watch in awe as the cutting-edge algorithm scours the extensive database to spot occurrences related to the brand.
Tags:
Supercharge the monitoring by adding relevant keywords. For the urlDNA example, throw in “urldna” and the tagline, like “The DNA test for websites.” You can even toss in specific page names to tailor the monitoring to precise needs.
Setting Up Your Rule:
Ready to dive in? Follow these straightforward steps:
- Click the Brand Monitor Button: Exclusive to registered users, this menu is the portal to brand monitoring excellence.
- Create a New Brand Monitor: Click on the “New Brand Monitor” button to kick off the setup process.
- Enter urlDNA Data: Fill in the essential information for the urlDNA rule, covering the rule name, brand assets, and relevant tags.
- Sit Back and Explore: With everything set up, witness the enchantment unfold as the system showcases all the pages aligning with the monitoring rule.
Join the league of content registered users who are already harnessing the power of urlDNA’s brand monitoring. Seize this extraordinary opportunity to fortify the brand’s online presence. Don’t let this chance slip by – sign up today and revel in a newfound level of control over urlDNA’s narrative! Start monitoring today at https://urldna.io
Credits:
Original blog post: https://blog.urldna.io/2024/01/brand-monitoring.html
Photo by Tobias Tullius on Unsplash


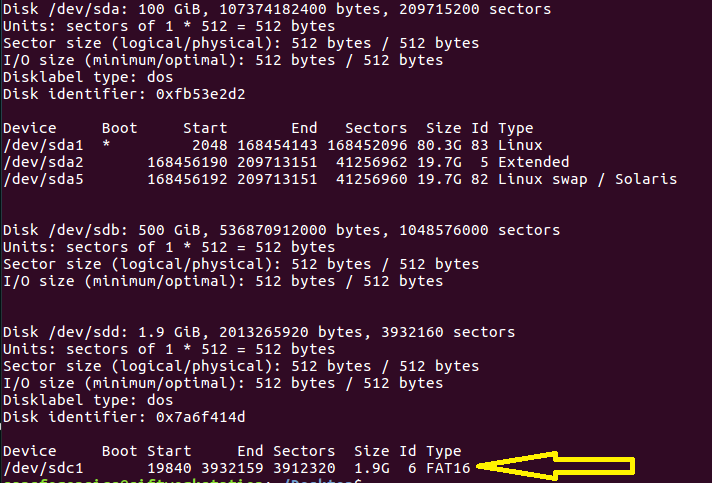
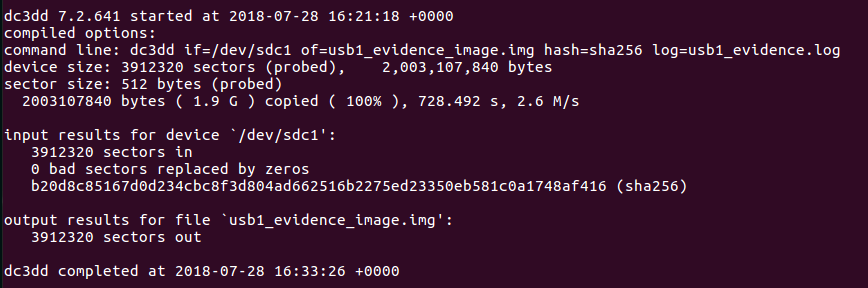
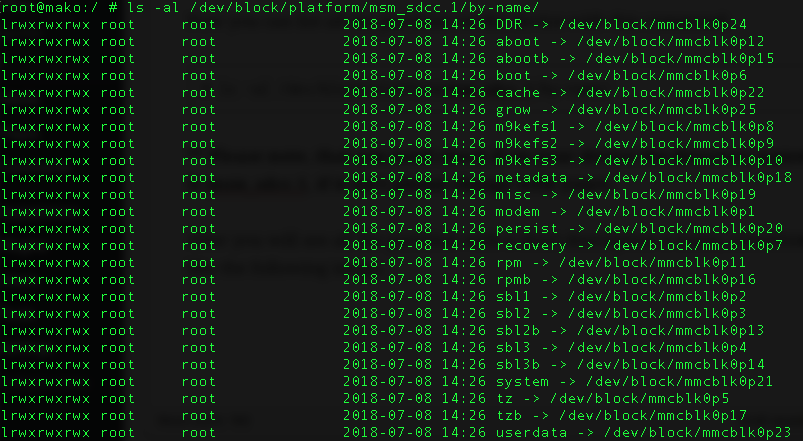
![[Note] Drive acquisition using dc3dd](https://www.forensics-matters.com/wp-content/uploads/2018/07/analogue-business-close-up-117729-825x510.jpg)